3D Diffuser Actor: Policy Diffusion with 3D Scene Representations
3D Diffuser Actor
Abstract
We marry diffusion policies and 3D scene representations for robot manipulation. Diffusion policies learn the action distribution conditioned on the robot and environment state using conditional diffusion models. They have recently shown to outperform both deterministic and alternative state-conditioned action distribution learning methods. 3D robot policies use 3D scene feature representations aggregated from a single or multiple camera views using sensed depth. They have shown to generalize better than their 2D counterparts across camera viewpoints. We unify these two lines of work and present 3D Diffuser Actor, a neural policy architecture that, given a language instruction, builds a 3D representation of the visual scene and conditions on it to iteratively denoise 3D rotations and translations for the robot’s end-effector. At each denoising iteration, our model represents end-effector pose estimates as 3D scene tokens and predicts the 3D translation and rotation error for each of them, by featurizing them using 3D relative attention to other 3D visual and language tokens. 3D Diffuser Actor sets a new state-of-the-art on RLBench with an absolute performance gain of 16.3% over the current SOTA on a multi-view setup and an absolute gain of 13.1% on a single-view setup. On the CALVIN benchmark, it matches the current SOTA in the setting of zero-shot unseen scene generalization. It also works in the real world from a handful of demonstrations. We ablate our model’s architectural design choices, such as 3D scene featurization and 3D relative attentions and show they all help generalization. Our results suggest that 3D scene representations and powerful generative modeling are keys to efficient robot learning from demonstrations.
Model architecture
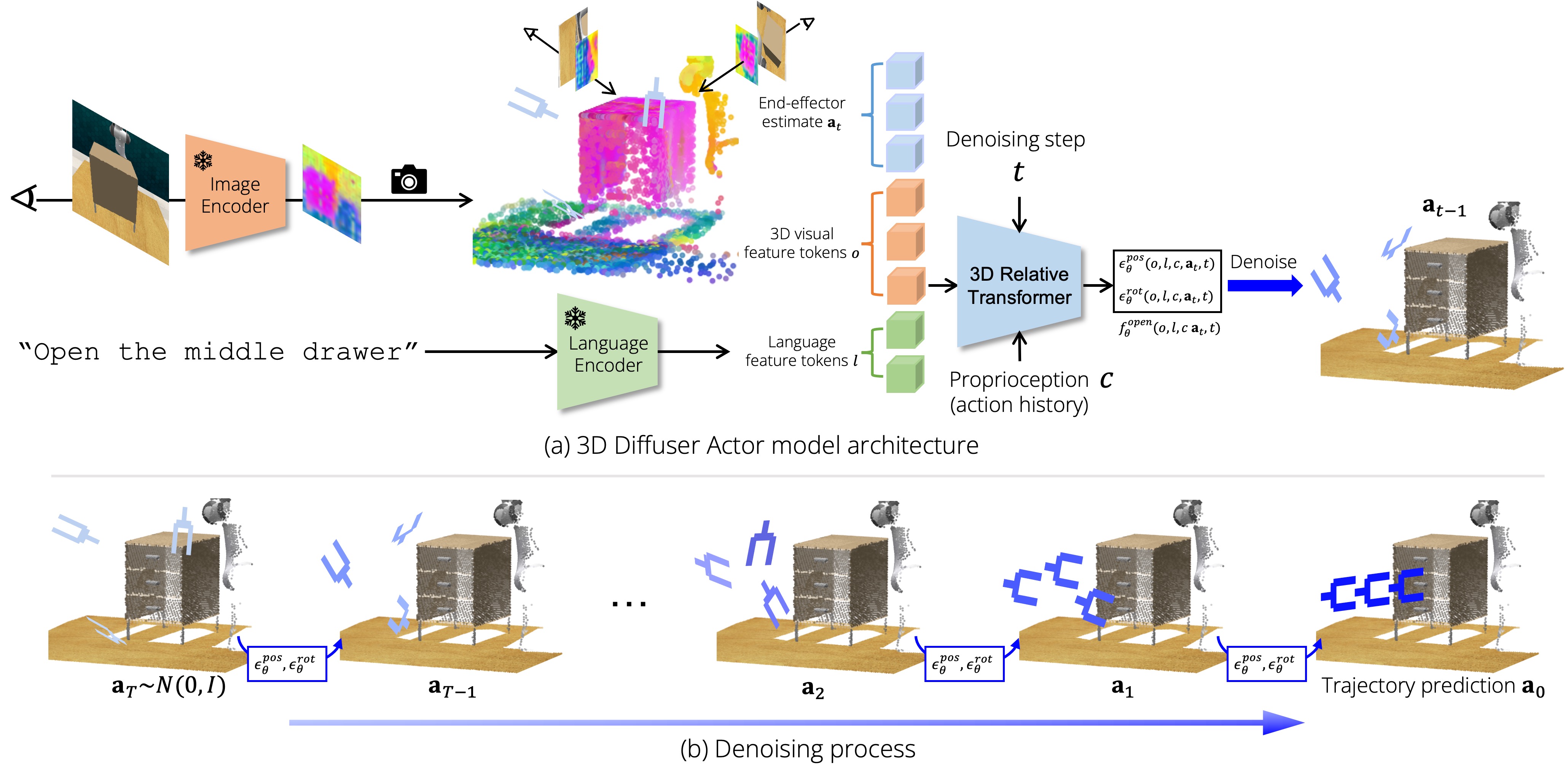
Top:3D Diffuser Actor is a denoising diffusion probabilistic model of the robot 3D trajectory conditioned on sensory input, language goals and proprioceptive information (action history). The model is a 3D relative position denoising transformer that featurizes jointly the scene and the current noisy estimate for robot’s future action trajectory through 3D relative-position attentions. 3D Diffuser Actor outputs position and rotation residuals for denoising, as well as the end-effector's state (open/close). Bottom: During inference, 3D Diffuser Actor iteratively denoises the current estimate for the robot's future trajectory, where the initial estimate is initialized from pure noise.
Visualization of the pose denoising process
We show 60 samples for the next predicted trajectory on CALVIN.
We show 60 samples for the next predicted keypose in the real-world. 3D Diffuser Actor captures all modes of equivalent behaviors for the different tasks: 3 modes for "picking up the grape", 2 modes for "inserting the peg in a hole" and 2 modes for "finding the mouse".
State-of-the-art on CALVIN
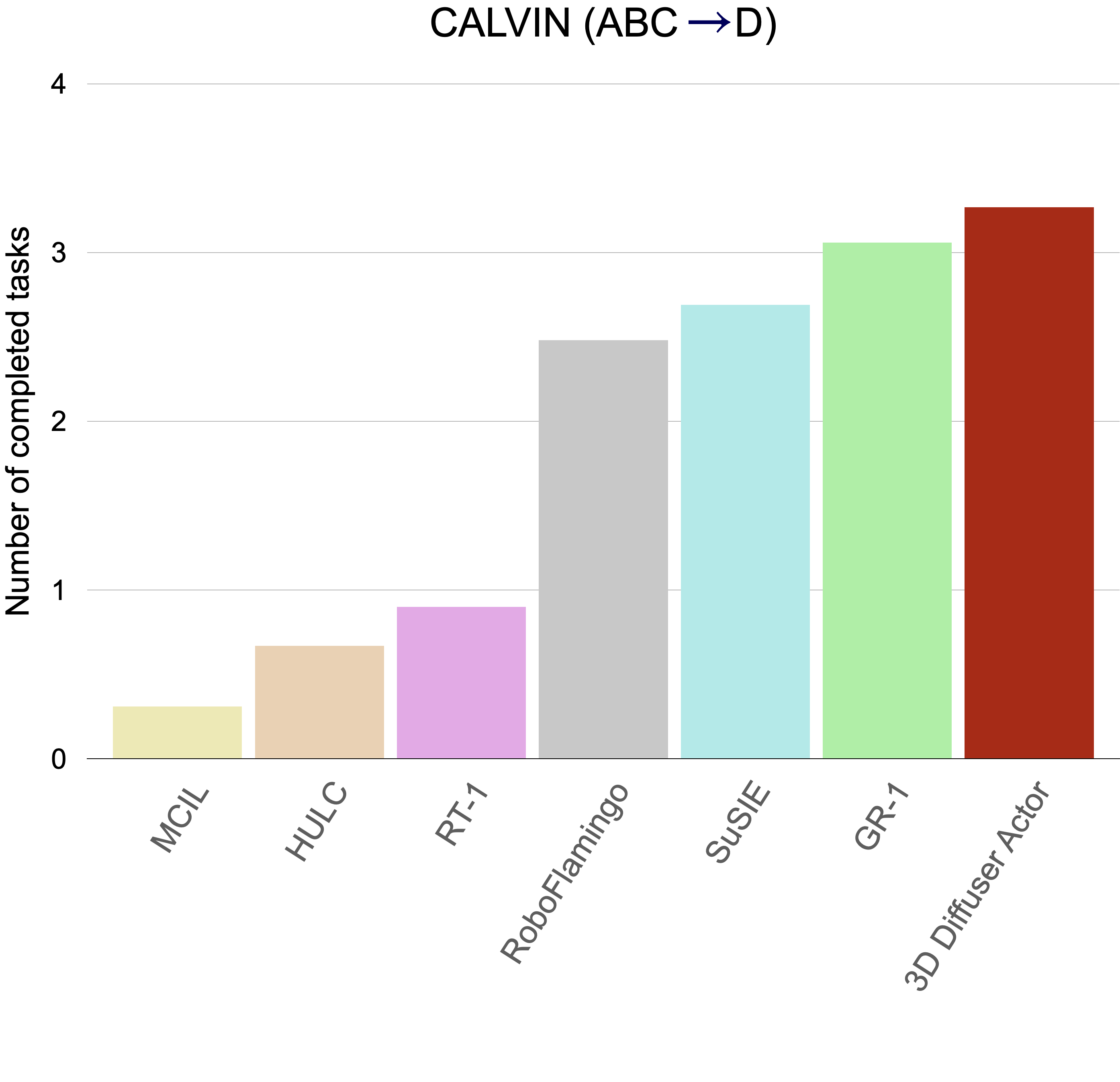
We test on CALVIN on the setting of zero-shot unseen-scene generalization. All models are trained on environments A, B, C and tested on environment D. 3D Diffuser Actor outperforms prior arts by a large margin, achieving 0.2 more sequential tasks, a 7% relative improvement.
State-of-the-art on RLBench
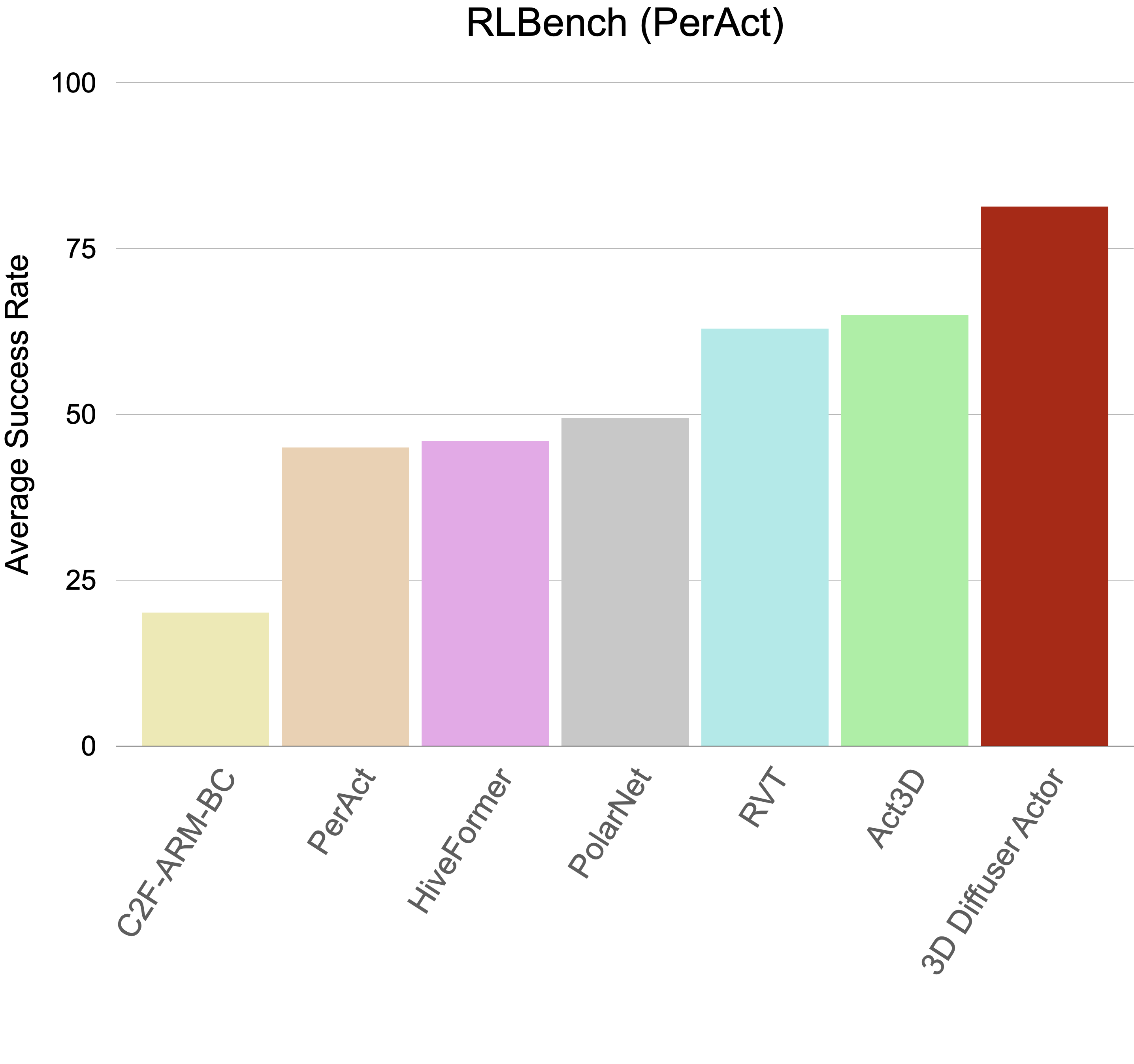
We test on a multi-task setup of 18 manipulation tasks on RLBench. All models use 4 camera views and 100 expert demonstrations for each task. 3D Diffuser Actor outperforms prior arts by a large margin, achieving 16.0 absolute performance gain on average across tasks.
3D Diffuser Actor in the real world
We train a multi-task 3D Diffuser Actor on 12 manipulation tasks in the real world to control a Franka Emika arm. All models use a single camera view and 15 demonstrations for each task. 3D Diffuser Actor is able to solve multimodal tasks in the real world.
BibTeX
@article{3d_diffuser_actor,
author = {Ke, Tsung-Wei and Gkanatsios, Nikolaos and Fragkiadaki, Katerina},
title = {3D Diffuser Actor: Policy Diffusion with 3D Scene Representations},
journal = {Arxiv},
year = {2024}
}